
Introduction
For those that are interested in automating tasks within your Tenable Security Center environment, you came to the right place. Although I do not have access to any Tenable products at this time, I do have some of the scripts that I had developed over the years which made my life a lot easier. Most of the time when we are in a position managing Security Center, we are charged with monitoring thousands of vulnerabilities across thousands of servers. The time spent performing miniscule tasks multiple times on a weekly basis can all be automated with a simple Python script. In this instructional blog post we will cover the Python script I developed in order to automate the process of downloading reports. As of the time of this post, Tenable does not provide a way to download more then one report through the UI. That is where the script comes in and saves some time. The script will need to be modified to meet your specific requirements but it can at least get you on the right path.
YouTube Video
Code
"""
Date : 20230920
Purpose: Tenable UI does not provide a way to bulk download weekly reports. This script will scrape the API endpoint for ID's that match weekly critera and download to reports folder.
"""
import requests
requests.packages.urllib3.disable_warnings()
import json
import csv
from datetime import datetime
import os
# Get request URL
url = 'https://<IP_ADDRESS>/rest/report?fields=id,name,startTime'
# Authentication
headers = { "x-apikey" : 'accesskey=<ACCESS_KEY>; secretkey=<SECRET_KEY>'}
# Get todays date
today = datetime.now().strftime('%Y-%m-%d')
# Get request
res = requests.get(url, headers=headers, verify=False)
# Convert request to json
data = res.json()
# Used to count of all reports in results
report_count = (len(data['response']['usable']))
# Create reports directory if it does not exist
reports_path = rf"C:\temp\{today}"
reports_path_exists = os.path.isdir(reports_path)
if reports_path_exists == False:
os.mkdir(reports_path)
counter = 0
# id_list not currently used for anything. May in the future be used to perform different functions
id_list = []
# iterate through each report, if converted time matches today grab ID and assign to list
while counter < report_count:
# Nested parsing
report = (data['response']['usable'][counter])
report_name = report['name']
report_id = report['id']
report_time = int(report['startTime'])
# Tenable time reports in Unix time stamp, convert and format
converted_report_time = datetime.utcfromtimestamp(report_time).strftime('%Y-%m-%d')
if "Whatever you are looking for" in report_name:
if converted_report_time == today:
id_list.append(str(report_id))
download_url = f'https://<IP_ADDRESS>/rest/report/{report_id}/download'
# r variable is used to store the content of post request to be saved to pdf file
r = requests.post(download_url, headers=headers, verify=False)
local_file_path = rf"C:\temp\{today}\{report_name}.pdf"
with open(local_file_path, 'wb') as file:
file.write(r.content)
counter = counter + 1
Breaking down the code
import requests
requests.packages.urllib3.disable_warnings()
import json
import csv
from datetime import datetime
import os
To start, we need to ensure we have the appropriate libraries imported. In this example, as explained in the video the csv library is not needed.
- Requests : Will be used to perform get/post requests to our Tenable server
- json : Will be used to convert and perform a number of actions on the data we receive from get request
- datetime : Will be used to get todays date in a variable and create folders and compare
- os : Used to interact with host OS and check if directory exists, if not create it.
# Get request URL
url = 'https://<IP_ADDRESS>/rest/report?fields=id,name,startTime'
# Authentication
headers = { "x-apikey" : 'accesskey=<ACCESS_KEY>; secretkey=<SECRET_KEY>'}
The url will be the first variable defined. You will need to modify this variable to match your address for Tenable. You will also need to replace <ACCESS_KEY> and <SECRET_KEY> with your own. You can get this from generating an API key, explained here.
# Get todays date
today = datetime.now().strftime('%Y-%m-%d')
# Get request
res = requests.get(url, headers=headers, verify=False)
# Convert request to json
data = res.json()
# Used to count of all reports in results
report_count = (len(data['response']['usable']))
- Next we will define the today variable. We do this by calling the now function inside of the datetime library. We can then use the strftime() function to format the date to meet our requirements.
- The res variable will store the get request information. For the get request we want to make sure we pass through the url and headers. You are not required to set the verify=False, I did this because at the time the SSL certificate was not valid. If you have a valid SSL and can authenticate without issue, then continue without.
- In order to process the information returned from the get request, we must convert it to json. Which is what we are doing when defining the data variable.
- Now that we have the data converted to JSON, we can parse it. Similar to iterating through a list, we can parse the data by doing something like data[‘response’][‘usable’]. We wrap that in len() function to get the number of reports that meet this criteria.
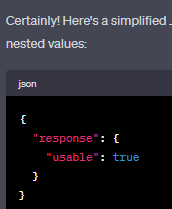
- Example: Using ChatGPT I generated a sample JSON string. This is not entirely correct but will get the point across.
- This would get us to the value of true. In the actual data it would have more values related to the reports.
# Create reports directory if it does not exist
reports_path = rf"C:\temp\{today}"
reports_path_exists = os.path.isdir(reports_path)
if reports_path_exists == False:
os.mkdir(reports_path)
- When we go to download the reports we will want to make sure we have defined a valid path.
- reports_path will be defined with a value of a temp directory on the C: and inside of this directory will be a directory similar to 2023-10-13. Using an f string we are able to use the today variable defined earlier.
- Before creating this folder, we will first use os.path.isdir() function passing through reports_path. If this path does exist it will be set to True, otherwise False.
- Lastly, a conditional statement the only is used if the path does not exist.
counter = 0
# id_list not currently used for anything. May in the future be used to perform different functions
id_list = []
# iterate through each report, if converted time matches today grab ID and assign to list
while counter < report_count:
# Nested parsing
report = (data['response']['usable'][counter])
report_name = report['name']
report_id = report['id']
report_time = int(report['startTime'])
# Tenable time reports in Unix time stamp, convert and format
converted_report_time = datetime.utcfromtimestamp(report_time).strftime('%Y-%m-%d')
if "Whatever you are looking for" in report_name:
if converted_report_time == today:
id_list.append(str(report_id))
download_url = f'https://<IP_ADDRESS>/rest/report/{report_id}/download'
# r variable is used to store the content of post request to be saved to pdf file
r = requests.post(download_url, headers=headers, verify=False)
local_file_path = rf"C:\temp\{today}\{report_name}.pdf"
with open(local_file_path, 'wb') as file:
file.write(r.content)
counter = counter + 1
Most of what is seen in this part of the script has already been explained. I will only explain parts that are new to the writeup.
- Counter. The counter variable is set to 0. This variable will be used to increment through the reports found in get request.
- While loop. The loop will only run when the integer stored in counter variable is less then the report_count (defined earlier using len())
# Nested parsing
report = (data['response']['usable'][counter])
In this section although I explained this earlier, I wanted to highlight why the counter variable was used.
- As I mentioned earlier the output from get request is nested json. Inside of this data variable within the ‘usable’ value is a list. Each value in this list is a separate report. Using the counter variable we are able to dynamically walkthrough the data. This is because each time the while loop finishes, the counter variable is increased by 1. So the next time this loop runs instead of report = (data[‘response’][‘usable’][1]) for example, it will be report = (data[‘response’][‘usable’][2]).
# Tenable time reports in Unix time stamp, convert and format
converted_report_time = datetime.utcfromtimestamp(report_time).strftime('%Y-%m-%d')
- This may vary in your script, but in our environment we have reports that are scheduled to run on a weekly basis. I run this script on the day these reports run. I use this as a way to capture the reports I need to download.
if "Whatever you are looking for" in report_name:
if converted_report_time == today:
id_list.append(str(report_id))
download_url = f'https://<IP_ADDRESS>/rest/report/{report_id}/download'
- We then use another conditional statement that looks at the report_name. For example maybe we were only looking for reports that have Windows in the name. This will vary from one environment to the next.
- A nested conditional statement is then used to define what reports we want further. Only continue onward if the report_time found in this Windows report matches today.
- If this report_time matches today, grab the report_id and append it to the id_list list.
- Before performing the post request we define the download_url by again using an f string to contain the {report_id} found that matches the various conditions set earlier.
r = requests.post(download_url, headers=headers, verify=False)
local_file_path = rf"C:\temp\{today}\{report_name}.pdf"
with open(local_file_path, 'wb') as file:
file.write(r.content)
counter = counter + 1
- To finish off the script we define the r variable by performing a post request. Again passing through the url, headers and very argument.
- We then define another path inside of the path created earlier to store the new .pdf document.
- Something new to me was writing to a file using ‘wb’. Instead of writing the actual string contents of this request it will write the binary value thus giving us the pdf format we need to view this report.
- Inside of the file.write() we pass through r.content. Content being the data from post request. Here you can also write things like r.status_code and a few others defined using the requests library.
- Last but not least, we increment our counter by 1 and start the loop over looking at the next position in the reports list.
Conclusion
That is going to close out this instructional write-up for automating the process within Tenable Security Center. We have a few more scripts that will automate even more, saving you a lot of time to perform other important tasks in the work place. Be sure to be a subscriber to the channel, and continue checking on the blog for updated posts.
As always, Never Stop Learning!